设置 Grafana 仪表板
现在您的节点已经启动并运行,您可能希望有一种便捷的方式一目了然地监控有关它的所有信息,以确保其正常运行(以及它为您产生了什么样的收益)。
有许多工具可以完成这项工作。
其中最受欢迎的工具之一叫做 Grafana - 一个易于使用的通用仪表板系统,您可以使用浏览器访问它。
Rocket Pool 开箱即支持 Grafana 及其依赖项;它甚至为每个共识客户端提供了预构建的仪表板。
例如,这是仪表板在 Hoodi 测试网络上的样子:
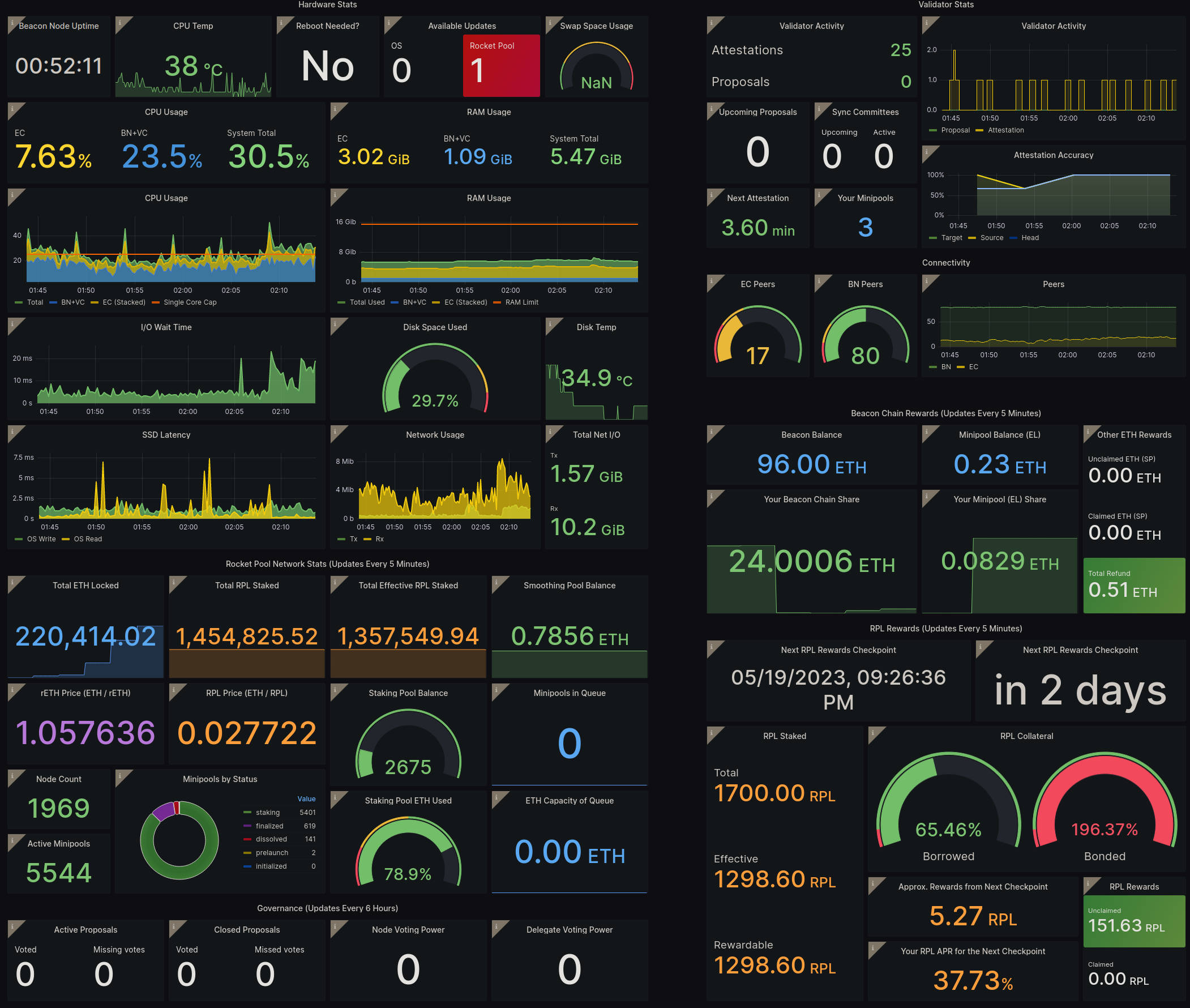
标准仪表板以方便的格式包含以下信息:
- 左上角: 有关您机器健康状况和性能的一些重要统计信息,以及任何待处理的系统更新
- 右上角: 您的验证者在信标链上的活动和性能,以及一些执行客户端和共识客户端的统计信息
- 左下角: 有关整个 Rocket Pool 网络的详细信息,供参考
- 右下角: 有关您的 staking 奖励的详细信息,包括 ETH 和 RPL
在本指南中,我们将向您展示如何启用 Rocket Pool 的指标系统,以便您可以使用此仪表板 - 甚至构建您自己的仪表板!
Rocket Pool 指标堆栈概述
如果您在 Smartnode 配置过程中选择启用指标,您的节点将添加以下进程:
- Prometheus - 一个数据收集、存储和报告系统,可捕获您在上面看到的所有指标(以及更多指标)并存储它们,以便可以随时间查看它们
- Prometheus Node Exporter - 一种收集有关您机器健康状况的信息(例如 CPU 使用率、RAM 使用率、可用磁盘空间和交换空间等)并将其报告给 Prometheus 的服务
- Grafana,通过在您的节点上托管的便捷网站公开 Prometheus 数据的工具
- 一组可选的自定义脚本,将向 Prometheus 报告任何可用的操作系统更新,以便您知道系统是否需要修补
默认配置将创建包含所有这些服务的 Docker 容器,这些容器与 Smartnode 的其余 Docker 容器一起运行。
它将在您的节点机器上打开一个端口用于 Grafana,以便您可以使用浏览器从本地网络上的任何机器访问其仪表板。
启用指标服务器
在 Docker 模式下启用指标是最简单的。
首先再次运行 Smartnode 配置命令:
rocketpool service config
转到 Monitoring / Metrics 部分并选中 Enable Metrics 复选框。
对于那些喜欢微调端口设置的人,您可以在这里进行。
请注意,所有这些端口都限制在 Docker 的内部网络中,Grafana 端口除外 - 该端口将在您的机器上打开(以便您可以从其他机器(如台式机或手机)通过浏览器访问它),因此如果默认端口与您已有的内容冲突,您可能需要更改它。
保存并退出,smartnode 将为您启动 Prometheus、Node Exporter 和 Grafana Docker 容器。
它还将修改您的共识客户端和验证者客户端,以便它们向 Prometheus 公开自己的指标。
为了最大的灵活性,默认不安装操作系统和 Rocket Pool 更新跟踪器,但过程很简单。
如果您想安装它,以便仪表板显示系统可用的更新数量,可以使用以下命令:
rocketpool service install-update-tracker
在底层,这将安装一个挂钩到操作系统软件包管理器的服务,定期检查更新,并将该信息发送到 Prometheus。
这项服务对于每个操作系统都不同,但已确认可在以下系统上运行:
- Ubuntu 20.04+
- Debian 9 和 10
- CentOS 7 和 8
- Fedora 34
注意
自动启用该服务与 SELinux 不兼容。
如果您的系统默认启用了 SELinux(CentOS 和 Fedora 就是这种情况),安装命令将使您_完成大部分工作_,但最后也会给您有关如何手动完成该过程的说明。
在此检查期间,它还会将您安装的 Rocket Pool Smartnode 版本与最新版本进行比较,如果有新版本可用,它会通知您。
如果您启用了更新跟踪器,则最后一步是使用以下命令重新启动 Node Exporter:
docker restart rocketpool_exporter
之后,您应该已经全部设置好了。
混合模式的工作方式与 Docker 模式类似;唯一的区别是您必须手动将启用指标的正确命令行标志添加到执行客户端和共识客户端服务定义中。
首先,我们将更新您的执行客户端。
打开您在安装执行客户端时创建的 systemd 单元文件,并确保它具有正确的标志,具体取决于您正在运行的客户端:
--metrics --metrics.addr 0.0.0.0 --metrics.port 9105
--Metrics.Enabled true --Metrics.ExposePort 9105
--metrics-enabled --metrics-host=0.0.0.0 --metrics-port=9105
接下来,我们将更新您的共识客户端。
打开您在安装共识客户端时创建的 systemd 单元文件,并确保它具有正确的标志,具体取决于您正在运行的客户端:
--metrics --metrics-address 0.0.0.0 --metrics-port 9100 --validator-monitor-auto
--metrics --metrics.address 0.0.0.0 --metrics.port 9100
--metrics --metrics-address=0.0.0.0 --metrics-port=9100
--monitoring-host 0.0.0.0 --monitoring-port 9100
如果您看到标志 --disable-monitoring,请将其删除。
--metrics-enabled=true --metrics-interface=0.0.0.0 --metrics-port=9100 --metrics-host-allowlist=*
如果您已经设置了这些标志并且正在使用不同的端口进行独立验证者监控,请保持原样并记下您正在使用的端口。
现在,向上滚动并按照本节的 Docker 选项卡中的说明完成该过程 - 请记住,当您运行 rocketpool service config 时,您必须将那里列出的端口替换为您使用的任何自定义端口。
仅建议高级用户本地安装 Grafana 和 Prometheus。它需要 Linux 管理技能,如 systemd、文件权限、用户和网络管理。
首先,确保您的执行客户端和共识客户端已启用指标。有关详细信息,请参阅"Hybrid"选项卡。
接下来,在官方下载页面上查看预构建的 prometheus 和 node_exporter 软件包。
为您的平台选择具有适当架构的软件包(amd64 或 arm64)。
建议使用最新的 LTS(长期支持)版本的 Prometheus。
例如,使用 wget 为 Linux amd64 下载 prometheus v2.45.3 LTS 和 node_exporter v1.7.0:
wget https://github.com/prometheus/prometheus/releases/download/v2.45.3/prometheus-2.45.3.linux-amd64.tar.gz
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
wget https://github.com/prometheus/alertmanager/releases/download/v0.26.0/alertmanager-0.26.0.linux-amd64.tar.gz
从下载的存档中提取 prometheus 和 node_exporter 可执行文件。
sudo tar -zxvf prometheus-2.45.3.linux-amd64.tar.gz -C /usr/local/bin --wildcards '*/prometheus' --strip-components=1
sudo tar -zxvf node_exporter-1.7.0.linux-amd64.tar.gz -C /usr/local/bin --wildcards '*/node_exporter' --strip-components=1
sudo tar -zxvf alertmanager-0.26.0.linux-amd64.tar.gz -C /usr/local/bin --wildcards '*/alertmanager' --strip-components=1
为 prometheus 和 alertmanager 配置创建目录。
sudo mkdir /etc/prometheus
sudo mkdir /etc/alertmanager
sudo mkdir /var/lib/prometheus
sudo mkdir /var/lib/alertmanager
创建文件 /etc/prometheus/prometheus.yml,内容如下:
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
scrape_timeout: 12s # Timeout must be shorter than the interval
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9091"]
- job_name: "node"
static_configs:
- targets: ["localhost:9103"]
# - targets: ['localhost:9103', 'node_hostname:9103']
- job_name: "eth1"
static_configs:
- targets: ["localhost:9105"]
# Uncomment the line below if you are using geth as Execution Client
#metrics_path: /debug/metrics/prometheus
- job_name: "eth2"
static_configs:
- targets: ["localhost:9100"]
- job_name: "validator"
static_configs:
- targets: ["validator:9101"]
- job_name: "rocketpool"
scrape_interval: 5m
scrape_timeout: 5m
static_configs:
- targets: ["node:9102"]
- job_name: "watchtower"
scrape_interval: 5m
scrape_timeout: 5m
static_configs:
- targets: ["watchtower:9104"]
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
注意
如果需要,请更改执行客户端和共识客户端的端口号。
您可能在与运行 prometheus 更改的主机不同的主机上运行您的节点。在这种情况下
在您的 rocketpool 节点主机上安装 node_exporter 并更新 node 作业的 targets 以包含您想要监控的所有机器。
如果您的执行客户端是 geth,还要调整 metrics_path - 它公开非标准的指标端点。
创建 /etc/alertmanager/alertmanager.yml,内容如下:
global:
# ResolveTimeout is the default value used by alertmanager if the alert does
# not include EndsAt, after this time passes it can declare the alert as resolved if it has not been updated.
# This has no impact on alerts from Prometheus, as they always include EndsAt.
# default = 5m
resolve_timeout: 5m
route:
# The labels by which incoming alerts are grouped together.
group_by: ["alertname"]
# How long to initially wait to send a notification for a group
# of alerts. Allows to wait for an inhibiting alert to arrive or collect
# more initial alerts for the same group.
group_wait: 30s
# How long to wait before sending a notification about new alerts that
# are added to a group of alerts for which an initial notification has
# already been sent. (Usually ~5m or more.)
group_interval: 5m
# How long to wait before sending a notification again if it has already been sent successfully for an alert.
repeat_interval: 4h
routes:
# severity=info: Don't send the follow-up resolved notification.
- match:
severity: info
continue: false
# The notification destination
receiver: "node_operator_no_resolved"
# all other alerts get sent notifications for the initial firing _and_ resolved notifications.
- receiver: "node_operator_default"
#match: We want this to match all alerts (severity=info is first though so it will stop)
# The notification destination
receiver: "node_operator_default"
receivers:
- name: "node_operator_default"
discord_configs:
- webhook_url: "https://discord.com/api/webhooks/1206697259694170212/_Pk1eVVgXFLdwU1k0rfwehSvNLiAQJytVV_Ze8QYOhupHnhiB5c8awPBTfuw41lN9GJk"
- name: "node_operator_no_resolved"
discord_configs:
- webhook_url: "https://discord.com/api/webhooks/1206697259694170212/_Pk1eVVgXFLdwU1k0rfwehSvNLiAQJytVV_Ze8QYOhupHnhiB5c8awPBTfuw41lN9GJk"
send_resolved: false
inhibit_rules:
# Inhibit rules mute a new alert (target) that matches an existing alert (source).
- source_match:
# if the existing alert (source) is severity=critical
severity: "critical"
target_match:
# and the new alert (target) is severity=warning
severity: "warning"
# and the alertname, job, and instance labels have the same value
equal: ["alertname", "job", "instance"]
为 prometheus 和 alertmanager 创建系统用户。
sudo useradd -r -s /sbin/nologin prometheus
sudo useradd -r -s /sbin/nologin alertmanager
更改 prometheus/alertmanager 文件所有权和权限。
sudo chown prometheus:prometheus /usr/local/bin/prometheus
sudo chown alertmanager:alertmanager /usr/local/bin/alertmanager
sudo chown prometheus:prometheus /usr/local/bin/node_exporter
sudo chown -R prometheus:prometheus /etc/prometheus
sudo chown -R alertmanager:alertmanager /etc/alertmanager
sudo chown -R prometheus:prometheus /var/lib/prometheus
sudo chown -R alertmanager:alertmanager /var/lib/alertmanager
sudo chmod u+sx,g+sx,o-wx /usr/local/bin/prometheus
sudo chmod u+sx,g+sx,o-wx /usr/local/bin/alertmanager
sudo chmod u+sx,g+sx,o-wx /usr/local/bin/node_exporter
为 node_exporter 服务配置创建文件 /lib/systemd/system/node-exporter.service。
[Unit]
Description=Node metrics exporter for Prometheus
Documentation=https://prometheus.io/docs/introduction/overview
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
Restart=on-failure
WorkingDirectory=/var/lib/prometheus
RuntimeDirectory=node-exporter
RuntimeDirectoryMode=0750
ExecStart=/usr/local/bin/node_exporter --web.listen-address=:9103
[Install]
WantedBy=multi-user.target
注意
如果您想更改 node_exporter 运行的端口,请修改
ExecStart 参数中的命令。默认端口是 9100。
为 prometheus 服务配置创建文件 /lib/systemd/system/prometheus.service。
[Unit]
Description=Prometheus instance
Documentation=https://prometheus.io/docs/introduction/overview
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
Restart=on-failure
WorkingDirectory=/var/lib/prometheus
RuntimeDirectory=prometheus
RuntimeDirectoryMode=0750
ExecStart=/usr/local/bin/prometheus --config.file /etc/prometheus/prometheus.yml --web.listen-address=:9091
[Install]
WantedBy=multi-user.target
注意
如果您想更改 prometheus 运行的端口,请修改
ExecStart 参数中的命令。默认端口是 9090。
为 alertmanager 服务配置创建文件 /lib/systemd/system/alertmanager.service。
[Unit]
Description=Alertmanager instance
Documentation=https://prometheus.io/docs/alerting/latest/alertmanager/
Wants=network-online.target
After=network-online.target
[Service]
User=alertmanager
Group=alertmanager
Type=simple
Restart=on-failure
WorkingDirectory=/var/lib/alertmanager
RuntimeDirectory=alertmanager
RuntimeDirectoryMode=0750
ExecStart=/usr/local/bin/alertmanager --config.file /etc/alertmanager/alertmanager.yml --web.listen-address=:9093
[Install]
WantedBy=multi-user.target
注意
如果您想更改 alertmanager 运行的端口,请修改
ExecStart 参数中的命令。默认端口是 9093。
让 systemd 知道新服务。
sudo systemctl daemon-reload
启用并启动 node-exporter 服务。
sudo systemctl enable node-exporter
sudo systemctl start node-exporter
检查服务状态以确保其正在运行。
sudo systemctl status node-exporter
启用并启动 prometheus 服务。
sudo systemctl enable prometheus
sudo systemctl start prometheus
启用并启动 alertmanager 服务。
sudo systemctl enable alertmanager
sudo systemctl start alertmanager
检查服务状态以确保其正在运行。
sudo systemctl status prometheus
sudo systemctl status alertmanager
为 Grafana 设置软件包存储库。
sudo apt-get update
sudo apt-get install -y apt-transport-https software-properties-common
sudo mkdir -p /etc/apt/keyrings/
wget -q -O - https://apt.grafana.com/gpg.key | gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
安装 Grafana。
sudo apt-get update
sudo apt-get install grafana
验证 /etc/grafana/grafana.ini 中的设置。将 http_port 更改为 3100,以与本文档中提供的其他部分保持一致。
配置数据源以在 Grafana 中可视化来自 Prometheus 的指标。创建文件 /etc/grafana/provisioning/datasources/prometheus.yml。
apiVersion: 1
deleteDatasources:
- name: Prometheus
orgId: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
orgId: 1
url: http://localhost:9091
basicAuth: false
isDefault: true
version: 1
editable: true
注意
如果您已更改 Prometheus 监听端口,请编辑
url。
启用并启动 Grafana 服务。
sudo systemctl daemon-reload
sudo systemctl enable grafana-server
sudo systemctl start grafana-server
检查 Grafana 是否正在运行。
sudo systemctl status grafana-server
差不多就是这样了。
配置防火墙以允许监控连接
注意
如果您按照保护您的节点部分中的参考启用了 UFW,则需要打开几个端口以允许 Prometheus 与您的执行客户端/共识客户端之间的本地连接。请按照以下步骤操作。
运行以下命令,并根据需要替换端口:
RP_NET=$(docker inspect rocketpool_net | grep -Po "(?<=\"Subnet\": \")[0-9./]+")
sudo ufw allow from $RP_NET to any port 9105 comment "Allow Prometheus access to Execution Client"
sudo ufw allow from $RP_NET to any port 9100 comment "Allow Prometheus access to Consensus Client"
sudo ufw allow from $RP_NET to any port 9103 comment "Allow Prometheus access to Exporter"
如果您的 RocketPool 节点和 Prometheus 位于不同的主机上,您需要在节点主机上配置防火墙,以允许从 Prometheus 主机 IP 到节点监控端口的传入流量。
您还需要在 Prometheus 机器上配置 UFW,以允许从 Prometheus 主机到 RocketPool 节点主机的出站流量。
节点主机 IP 为 192.168.1.5,Prometheus 主机 IP 为 192.168.1.6,节点的 UFW 规则为:
sudo ufw allow from 192.168.1.6 to any port 9100:9105 proto tcp comment 'Allow Prometheus host to scrape metrics of this host'
Prometheus 主机的规则为:
sudo ufw allow out from any to 192.168.1.5 port 9100:9105 proto tcp comment 'Allow this host to scrape node metrics'
假设您的 Grafana 监听端口是 3100,请继续阅读以了解如何在网络中公开 Grafana。
然后,您可以打开防火墙以允许外部设备访问您的 Grafana 仪表板。
如果您想从本地网络内的任何机器访问 Grafana,但拒绝其他任何地方的访问,请使用此选项。
这将是最常见的用例。
请先检查您的本地网络是否使用 192.168.1.xxx 结构。
如果您的本地网络使用不同的地址结构(例如 192.168.99.xxx),您可能需要更改以下命令以匹配您的本地网络配置。
# This assumes your local IP structure is 192.168.1.xxx
sudo ufw allow from 192.168.1.0/24 proto tcp to any port 3100 comment 'Allow grafana from local network'
如果您的 Rocket Pool 节点未连接到与您查看 Grafana 的设备相同的子网,请使用此选项。当您的节点直接连接到 ISP 的调制解调器,而您用来查看 Grafana 的设备连接到辅助路由器时,可能会发生这种情况。
请先检查您的本地网络是否使用 192.168.1.xxx 结构。
如果您的本地网络使用不同的地址结构(例如 192.168.99.xxx),您可能需要更改以下命令以匹配您的本地网络配置。
# To allow any devices in the broader subnet
# for example allowing 192.168.2.20 to access
# grafana on 192.168.1.20
sudo ufw allow from 192.168.1.0/16 proto tcp to any port 3100 comment 'Allow grafana from local subnets'
这将允许您从任何地方访问 Grafana。
如果您想从本地网络外部访问它,您仍然需要在路由器设置中转发 Grafana 端口(默认 3100)。
# Allow any IP to connect to Grafana
sudo ufw allow 3100/tcp comment 'Allow grafana from anywhere'
设置 Grafana
现在指标服务器已准备就绪,您可以使用本地网络上的任何浏览器访问它。
有关 Smartnode 安装模式,请参阅下面的选项卡。
导航到以下 URL,根据您的设置替换变量:
http://<your node IP>:<grafana port>
例如,如果您的节点 IP 是 192.168.1.5,并且您使用默认的 Grafana 端口 3100,那么您将在浏览器中访问此 URL:
您将看到如下登录屏幕:

默认 Grafana 信息是:
Username: admin
Password: admin
然后,系统会提示您更改 admin 账户的默认密码。
选择一个强密码,不要忘记它!
提示
如果您丢失了管理员密码,可以使用节点上的以下命令重置它:
docker exec -it rocketpool_grafana grafana-cli admin reset-admin-password admin
sudo grafana-cli admin reset-admin-password admin
您将能够再次使用默认的 admin 凭据登录 Grafana,然后系统将提示您更改 admin 账户的密码。
多亏了社区成员 tedsteen 的工作,Grafana 将自动连接到您的 Prometheus 实例,以便它可以访问它收集的指标。
您所需要做的就是获取仪表板!
导入 Rocket Pool 仪表板
现在您已将 Grafana 连接到 Prometheus,您可以导入标准仪表板(或者如果您熟悉该过程,可以使用它提供的指标构建自己的仪表板)。
首先转到 Create 菜单(右侧栏上的加号图标)并点击 Import:
当提示在 Import via grafana.com 框中输入仪表板 ID 时,输入 21863 或使用完整 URL ((https://grafana.com/grafana/dashboards/24900-rocket-pool-dashboard-v1-4-0/),然后按 Load 按钮。
您将在此处看到一些有关仪表板的信息,例如其名称以及您希望将其存储在哪里(默认的 General 文件夹就可以了,除非您使用大量仪表板并希望对其进行组织)。
在底部的 Prometheus 下拉菜单下,您应该只有一个标记为 Prometheus (default) 的选项。
选择此选项。
您的屏幕应如下所示:
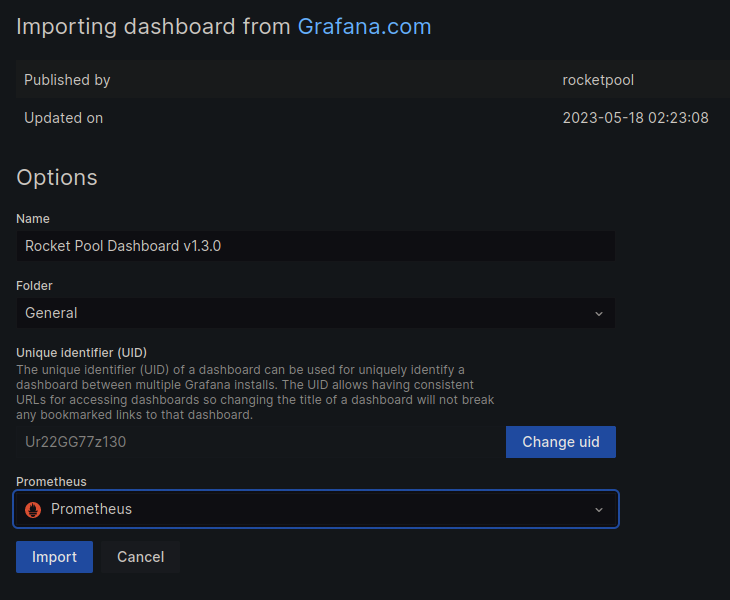
如果您的匹配,请单击 Import 按钮,您将立即进入新仪表板。
乍一看,您应该会看到有关您的节点和验证者的大量信息。
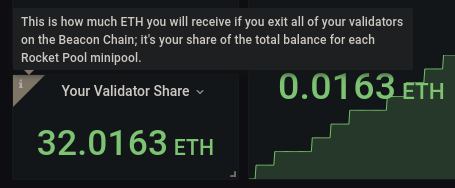
每个框的左上角都有一个方便的工具提示(i 图标),您可以将鼠标悬停在上面以了解更多信息。
例如,这是 Your Validator Share 框的工具提示:
但是,我们还没有完成设置 - 还有一些配置要做。
注意
由于 Shapella 提供 skimmed 奖励的方式,一些框(特别是 APR 框)已被暂时禁用。
它们将在可以正确跟踪历史奖励的 Smartnode 未来版本中再次启用。
根据您的系统定制硬件监视器
现在仪表板已启动,您可能会注意到一些框是空的,例如 SSD Latency 和 Network Usage。
我们必须根据您的特定硬件定制仪表板,以便它知道如何捕获这些内容。
CPU 温度
要更新您的 CPU 温度计,请单击 CPU Temp 框的标题,然后从下拉菜单中选择 Edit。
您的屏幕现在看起来像这样:
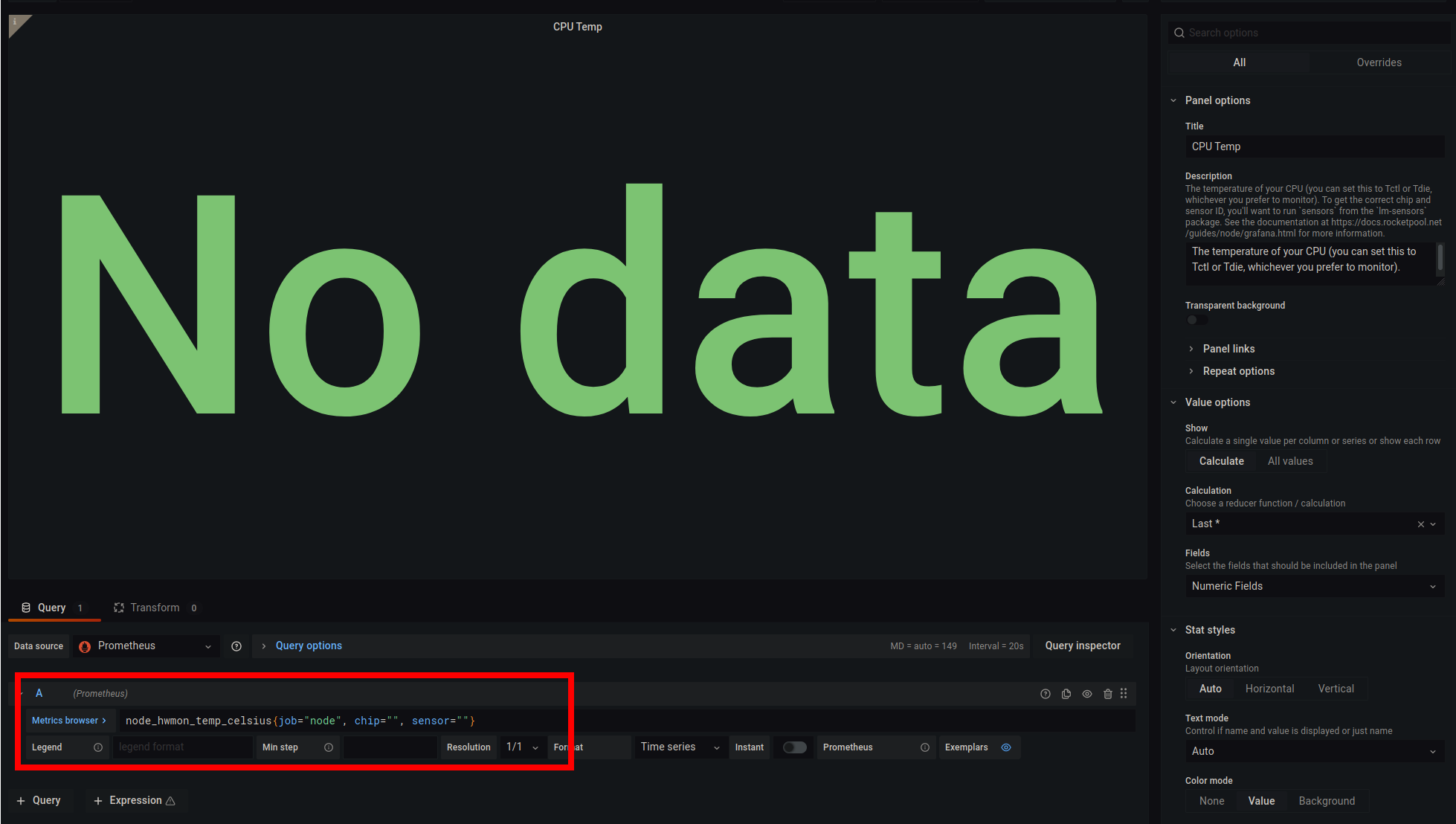
这是 Grafana 的编辑模式,您可以在其中更改显示的内容及其外观。
我们对用红色突出显示的查询框感兴趣,它位于 Metrics browser 按钮的右侧。
默认情况下,该框中包含以下内容:
node_hwmon_temp_celsius{job="node", chip="", sensor=""}
此文本中有两个字段当前为空:chip 和 sensor。
这些对每台机器都是唯一的,因此您必须根据机器提供的内容填写它们。
为此,请按照以下步骤操作:
- 删除
, sensor="" 部分,使其以 chip=""} 结尾。为了清楚起见,整个内容现在应该是 node_hwmon_temp_celsius{job="node", chip=""}。
- 将光标放在
chip="" 的引号之间,然后按 Ctrl+Spacebar。这将弹出一个自动完成框,其中包含可用选项,如下所示:
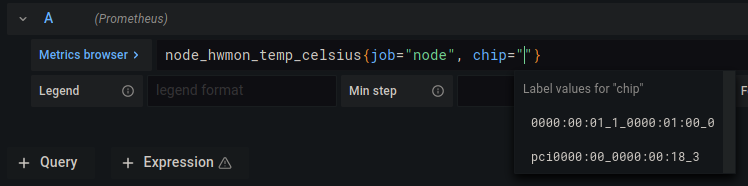
- 选择与您系统的 CPU 对应的选项。
- 选择后,将
, sensor="" 添加回字符串。将光标放在 sensor="" 的引号之间,然后按 Ctrl+Spacebar 以获得另一个自动完成菜单。选择您要监控的传感器。
提示
如果您不知道哪个 chip 或 sensor 是正确的,您将不得不尝试所有它们,直到找到看起来正确的那个。为了帮助解决这个问题,请安装 lm-sensors 软件包(例如,在 Debian / Ubuntu 上使用 sudo apt install lm-sensors)并运行 sensors -u 命令,以提供您的计算机拥有的传感器。您可以尝试根据名称和 ID 将 Grafana 列表中的芯片 ID 与您在此处看到的内容相关联。
例如,这是我们的 sensors -u 命令的输出之一:
k10temp-pci-00c3
Tctl:
temp1_input: 33.500
Tdie:
temp2_input: 33.500
在我们的例子中,Grafana 中的相应芯片是 pci0000:00_0000:00:18_3,相应的传感器是 temp1。
对您的选择感到满意后,单击屏幕右上角的蓝色 Apply 按钮以保存设置。
注意
并非所有系统都公开 CPU 温度信息 - 特别是虚拟机或基于云的系统。
如果您的 chip 自动完成字段中没有任何内容,可能就是这种情况,您将无法监控 CPU 温度。
SSD 延迟
SSD Latency 图表跟踪读/写操作所需的时间。
这有助于评估 SSD 的速度,因此如果验证者性能不佳,您就知道它是否成为瓶颈。
要更新要在图表中跟踪的 SSD,请单击 SSD Latency 标题并选择 Edit。
此图表有四个查询字段(四个文本框),总共有八个 device="" 部分。
您需要使用要跟踪的设备更新前四个部分。
只需将光标放在引号之间,然后按 Ctrl+Spacebar 即可获得 Grafana 的自动完成列表,并从那里为每个 device="" 部分选择正确的选项。
您希望从最左边的空设置开始,否则自动完成列表可能不会出现。
提示
如果您不知道要跟踪哪个设备,请运行以下命令:
这将输出一个显示设备和分区列表的树,例如:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
...
loop25 7:25 0 132K 1 loop /snap/gtk2-common-themes/9
loop26 7:26 0 65,1M 1 loop /snap/gtk-common-themes/1515
nvme0n1 259:0 0 238,5G 0 disk
├─nvme0n1p1 259:1 0 512M 0 part /boot/efi
├─nvme0n1p2 259:2 0 150,1G 0 part /
├─nvme0n1p3 259:3 0 87,4G 0 part
└─nvme0n1p4 259:4 0 527M 0 part
如果您在 Smartnode 安装期间没有将 Docker 的默认位置更改为其他驱动器,那么您要跟踪的磁盘将是安装操作系统的磁盘。
在 MOUNTPOINT 列中查找标记为 / 的条目,然后按照该条目返回到其父设备(TYPE 列中带有 disk 的设备)。
通常,SATA 驱动器为 sda,NVMe 驱动器为 nvme0n1。
如果您确实将 Docker 的默认位置更改为其他驱动器,或者如果您正在运行混合/本地设置,您应该能够使用相同的"跟随挂载点"技术来确定链数据所在的设备。
或者,您还可以在系统上跟踪第二个磁盘的延迟。
这是针对将操作系统和链数据保存在单独驱动器上的人们。
要进行设置,只需按照上述说明对最后两个查询字段进行操作,将 device="" 部分值替换为您要跟踪的磁盘的值。
对您的选择感到满意后,单击屏幕右上角的蓝色 Apply 按钮以保存设置。
网络使用情况
此图表跟踪您通过特定网络连接发送和接收的数据量。
正如您所料,仪表板需要知道您希望它跟踪哪个网络。
要更改它,请单击 Network Usage 标题并选择 Edit。
此图表有两个查询字段,总共有两个 device="" 部分。
您需要使用要跟踪的网络更新这些内容。
将光标放在引号之间,然后按 Ctrl+Spacebar 即可获得 Grafana 的自动完成列表,并从那里为每个 device="" 部分选择正确的选项。
提示
如果您不知道要跟踪哪个设备,请运行以下命令:
输出将如下所示:
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 192.168.1.1 0.0.0.0 UG 100 0 0 eth0
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
192.168.1.1 0.0.0.0 255.255.255.255 UH 100 0 0 eth0
查看 Destination 列中值为 default 的行。
沿着该行一直到 Iface 列。
那里列出的设备是您要使用的设备 - 在本例中为 eth0。
对您的选择感到满意后,单击屏幕右上角的蓝色 Apply 按钮以保存设置。
总网络 I/O
这会跟踪您发送和接收的数据总量。
如果您的 ISP 限制您每月使用一定数量的数据,您可能会发现它很有用。
设置与上面的 Network Usage 框相同,因此只需按照这些说明操作即可。
使用的磁盘空间
这会监控您的操作系统磁盘有多满,以便您知道何时该清理了(如果您的链数据位于同一驱动器上,则该修剪 Geth 或 Nethermind 了)。
步骤与上面的 SSD Latency 框相同,因此只需按照这些说明操作即可。
提醒一下,您需要的驱动器是包含 MOUNTPOINT 列中带有 / 的分区的驱动器,因为那将是您的操作系统驱动器。
将其填写到第一个查询字段中。
或者,您还可以跟踪系统上第二个磁盘的可用空间。
这是针对将操作系统和链数据保存在单独驱动器上的人们。
通过遵循相同的过程进行设置,但不是查看 MOUNTPOINT 列中哪个分区具有 /,而是要查找具有第二个驱动器挂载点的分区。
使用与该分区关联的磁盘更新第二个查询字段。
磁盘温度
这会跟踪操作系统磁盘的当前温度。步骤与上面的 CPU Temp 框相同,因此只需按照这些说明操作即可,将 CPU 芯片和传感器值替换为操作系统磁盘的值。将这些值填写到第一个查询字段中。
或者,您还可以跟踪系统上第二个磁盘的当前温度。通过遵循相同的过程进行设置,将芯片和传感器值替换为第二个驱动器的值。将这些值填写到第二个查询字段中。
自定义仪表板
虽然标准仪表板尝试很好地捕获您希望一目了然看到的所有内容,但自定义 Grafana 仪表板非常容易。
您可以添加新图表,更改图表的外观,移动内容等等!
查看 Grafana 的教程页面,了解如何使用它并根据您的喜好进行设置。
自定义指标堆栈
Rocket Pool 指标堆栈中使用的工具提供了超出默认 Rocket Pool 安装中包含的内容的大量配置选项。本节包含不同用例的配置示例。
一般来说,Grafana 配置选项应该使用 override/grafana.yml 中的环境变量传递。可以使用以下语法将任何配置选项转换为环境变量:
GF_<SectionName>_<KeyName>
用于发送电子邮件的 Grafana SMTP 设置
要从 Grafana 发送电子邮件,例如用于警报或邀请其他用户,需要在 Rocket Pool 指标堆栈中配置 SMTP 设置。
请参阅 Grafana SMTP 配置页面以供参考。
在文本编辑器中打开 ~/.rocketpool/override/grafana.yml。
在 x-rp-comment: Add your customizations below this line 行下方添加一个 environment 部分,将下面的值替换为 SMTP 提供商的值。
version: "3.7"
services:
grafana:
x-rp-comment: Add your customizations below this line
environment:
## SMTP settings start, replace values with those of your SMTP provider
- GF_SMTP_ENABLED=true
- GF_SMTP_HOST=mail.example.com:`port` # Gmail users should use smtp.gmail.com:587
- GF_SMTP_USER=admin@example.com
- GF_SMTP_PASSWORD=password
- GF_SMTP_FROM_ADDRESS=admin@example.com
- GF_SMTP_FROM_NAME="Rocketpool Grafana Admin"
## SMTP server settings end
在文本编辑器中打开 /etc/grafana/grafana.ini。查找 [smtp] 部分并对其进行更新,将下面的值替换为 SMTP 提供商的值。
[smtp]
enabled = true
host = mail.example.com:`port` # Gmail users should use smtp.gmail.com:587
user = admin@example.com
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
password = """passw0rd"""
from_address = admin@example.com
from_name = "Rocketpool Grafana Admin"
进行这些修改后,运行以下命令以应用更改:
docker stop rocketpool_grafana
rocketpool service start
sudo systemctl restart grafana-server
要测试 SMTP 设置,请转到 Alerting 菜单并单击 Contact points。
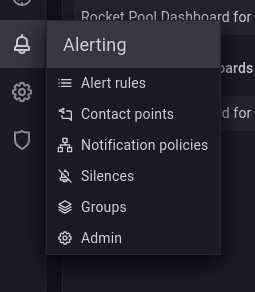
单击 New contact point 并选择 Email 作为联系点类型。
在 Addresses 部分输入电子邮件地址,然后单击 Test。
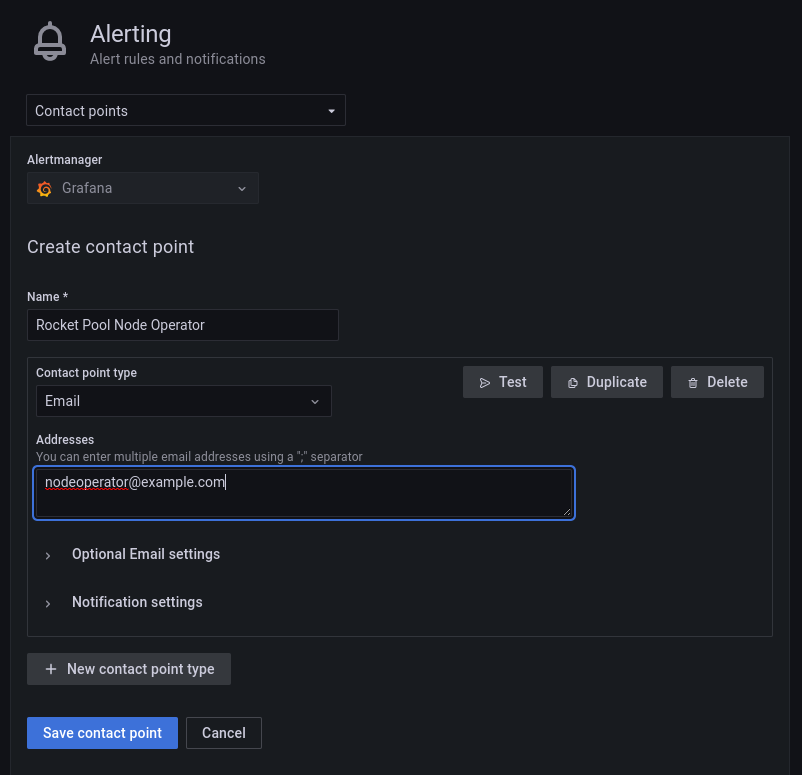
检查是否收到了测试电子邮件。
完成后单击 Save contact point*。